Back
Up
Next
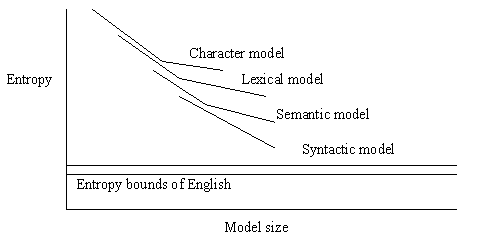
Model Performance vs. Size
Data compression measures model performance
If Q is an estimate of a model, P, then entropy, H =
Sx P(x) log 1/Q(x)
is minimized when Q = P (Shannon, 1949).
H is the expected compression ratio when Q is used to compress a random
sample with distribution P (i.e. text).
Model size (cost) = H ´ training set
size
Memory required to store the training set.
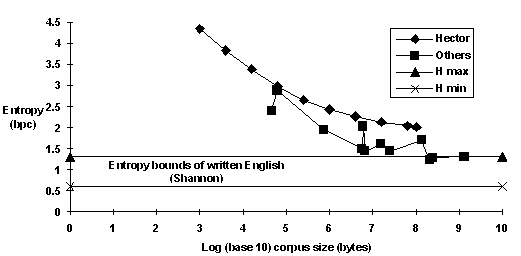
My goal